

今天終於要補”過度最佳化”第二篇的文章了
上一篇傳送門:點我
上一篇提到的是合理、有邏輯的交易策略比較能避免過度最佳化的問題
並且有提到
去除過度最佳化的三個部分照順序分別為:
1) 交易策略
2) 優化時的挑選參數
3) 使用testing data
所以今天要講解的是優化的參數挑選跟testing data
我們先來看一下在回測頁面的EA交易屬性部分,就可以來設定優化的參數跟範圍
今天艾比優化Lucy這支EA的四個參數,分別是:
1.獲利倍數 (從2開始/每次加1/到5結束,共4種)
2.參數 (從10開始/每次加10/到60結束,共6種)
3.距離 (從50開始/每次加50/到250結束,共5種)
4.小於倍數 (從0.5開始/每次加0.1/到0.9結束,共5種)

不使用基因演算法總共要跑600次 (基本上低於2000次都是滿快速輕鬆的)
當你要優化的參數比較多或是範圍比較廣,這樣會要跑太多次,會過久
就建議勾選基因演算法來優化
那我們今天的範例就是不使用基因演算法的
所以他就會從第一個要被優化的參數開始依序一個一個的去跑結果出來
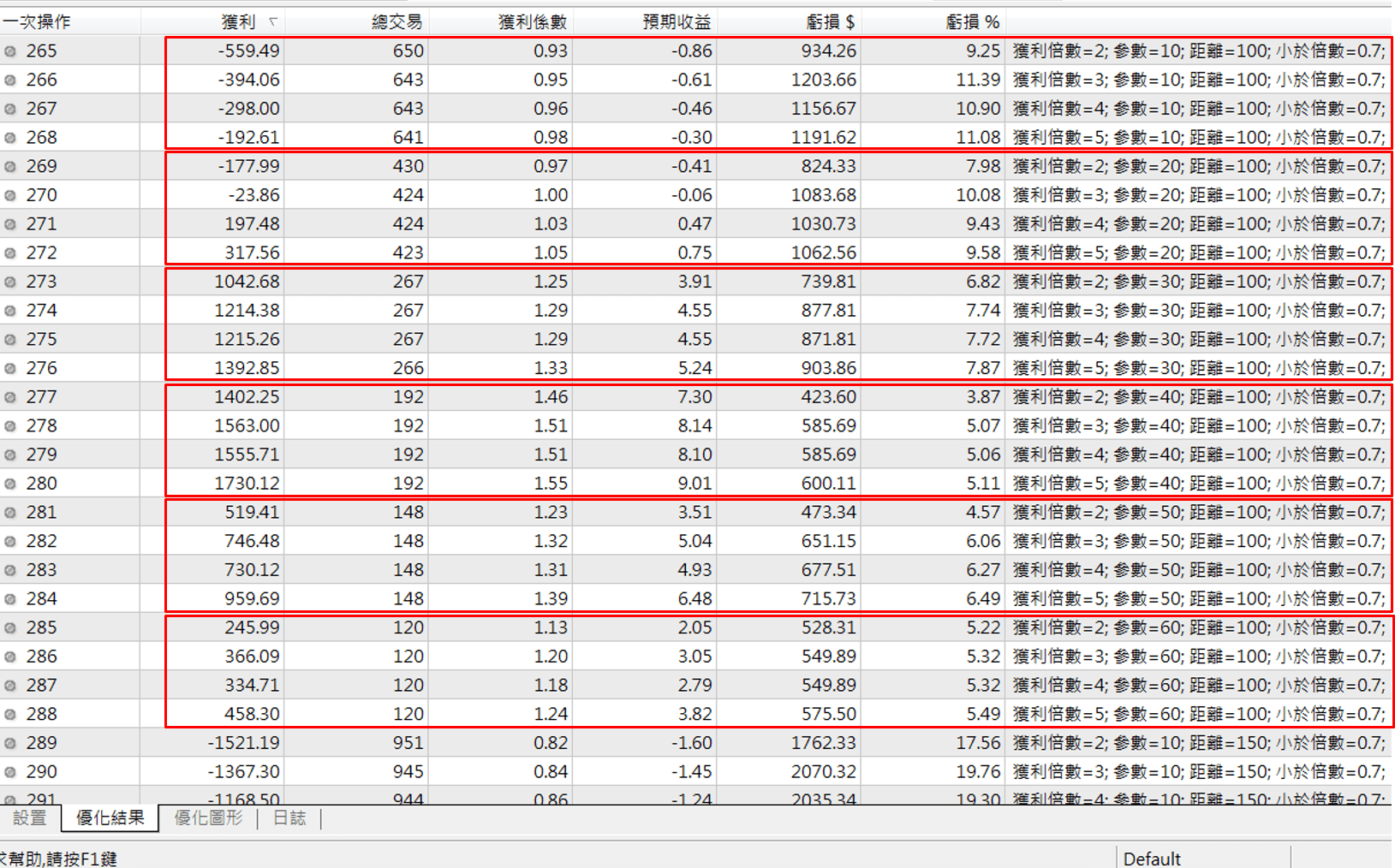
那我們看一下下面這兩張正在優化當中的結果圖表
首先他會固定後面三個參數
然後優化第一個”獲利倍數”的參數,依序測試 2、3、4、5
然後再換調整第二個”參數”這個參數變成20
再去優化第一個”獲利倍數”的參數,一樣依序測試 2、3、4、5
以此類推…

等待優化逐漸跑完
我們就要來找”參數高原”了
參數有分為“高原參數”與”孤島參數”
那我們要去使用”高原的參數”,千萬不要去使用到”孤島的參數”
孤島參數代表這組參數非常敏感,可能只要稍微變動,就會造成獲利能力失效
就是落入了過度最佳化的陷阱了
而高原參數則是相對穩定,就算有些微改變,其每組的績效變化是不大的
使用這樣的參數才相對能確保EA在未來行情的獲利能力
關於參數高原,大家可以去google一下,可以看到很多立體圖示說明 (艾比沒這東西)
看立體圖示應該比較好理解這個概念
(立體圖只能去優化兩個參數時才能顯示,超過兩個就無法了)
我們看回上面的兩張優化結果圖
分別在”距離”等於100跟等於150的狀況下,我們可以看得出來,”參數”等於40的的表現都是比較好的
那在”獲利倍數”來看,整體獲利倍數等於5的表現也都是比較好的
所以這個”參數”40跟”獲利倍數”5就是代表是高原的參數
那我們再來看到全部都跑完的結果表
預設他會按照最高到最低的”Balance”,也就是獲利來排序
 從上圖這個經過排序的圖表,不知道大家能不能看出參數高原在哪
從上圖這個經過排序的圖表,不知道大家能不能看出參數高原在哪
艾比通常會選前幾名,並且有參數高原的參數來做testing data的測試
大概就是
獲利倍數是4或5
參數是40~60
距離是150
小於倍數0.8
這樣的組合
挑選高原參數其實很憑個人主觀意識
但只要是落在參數高原當中的範圍就沒有關係
因為未來的行情是未知的,我們只是要確保能找到一組表現穩定的參數範圍
找到參數之後,接下來就要去做testing data的測試
什麼是testing data呢?
就是一段歷史價格資料,但並不在我們用來優化找參數的期間當中
例如
使用2010~2015年的歷史資料來優化尋找參數
再用2016~2018年的歷史資料當作testing data
這個testing data主要是去模擬2016~2018年這段時間假裝當作是未來未知的行情
去測試我們找出來的參數,在未知的行情下是否一樣擁有獲利的能力
看下圖
紅線左邊是我們用優化去找出的參數跑出來的表現
紅線右邊則是teating data的表現
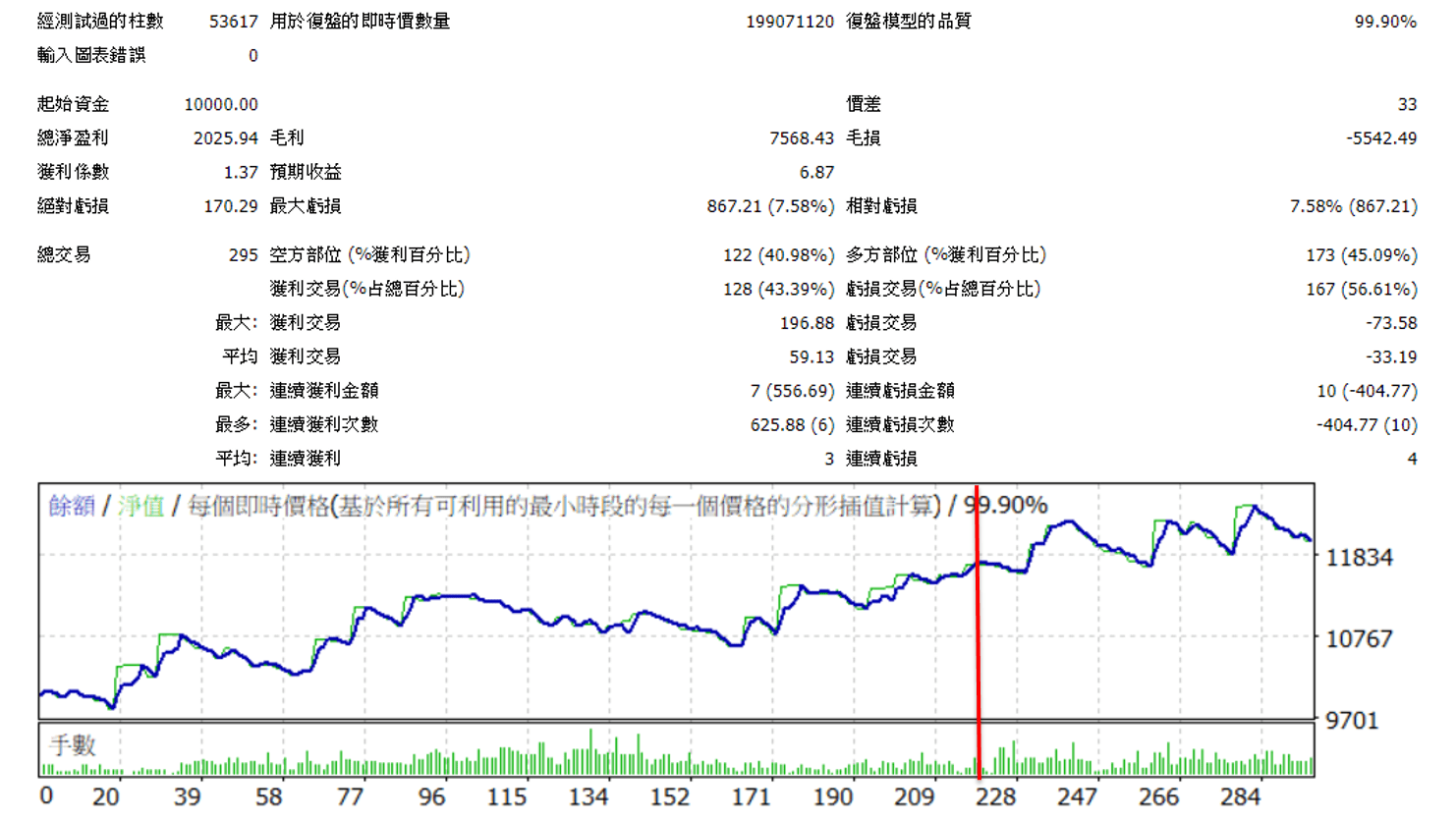
我們可以看到
在模擬未來未知的行情的testing data的表現中,績效有在持續創高,並且DD跟前面的表現是差不多的,DD並沒有增大
這樣這組挑選出來的參數艾比就會拿來使用
不過一般來說,在testing data中的表現通常會比較差
因為前面2010~2015整段時間都是用來擬合參數用的,所以這段期間表現較好是應該的
那我們去做這樣的兩段性測試
就是為了要避免找出”過度最佳化”的參數
這就是一個 機器學習 machine learning 當中 training & testing data 的概念了喔
你也可以用孤島的參數去測試看看testing data這段
通常績效會一路往下掉的
那如果你使用了這種過度最佳化的參數去跑實盤,去跑未來未知的行情的話,非常有可能會讓你的帳戶造成虧損,所以不得不注意啊!
哇~今天的文好長啊
不知道大家能不能清楚明白,因為艾比認為這部分真的是開發策略當中最重要的一環了
以上就是避免EA過度最佳化的幾個方式,提供給大家,希望大家能創造出在未來一樣可以有好表現的交易策略
相關內容